High Availability (HA) in Neon
Understanding Neon's approach to High Availability
At Neon, our serverless architecture is resilient by default, with the separation of storage from compute giving us flexibility in designing High Availability (HA) solutions for each layer.
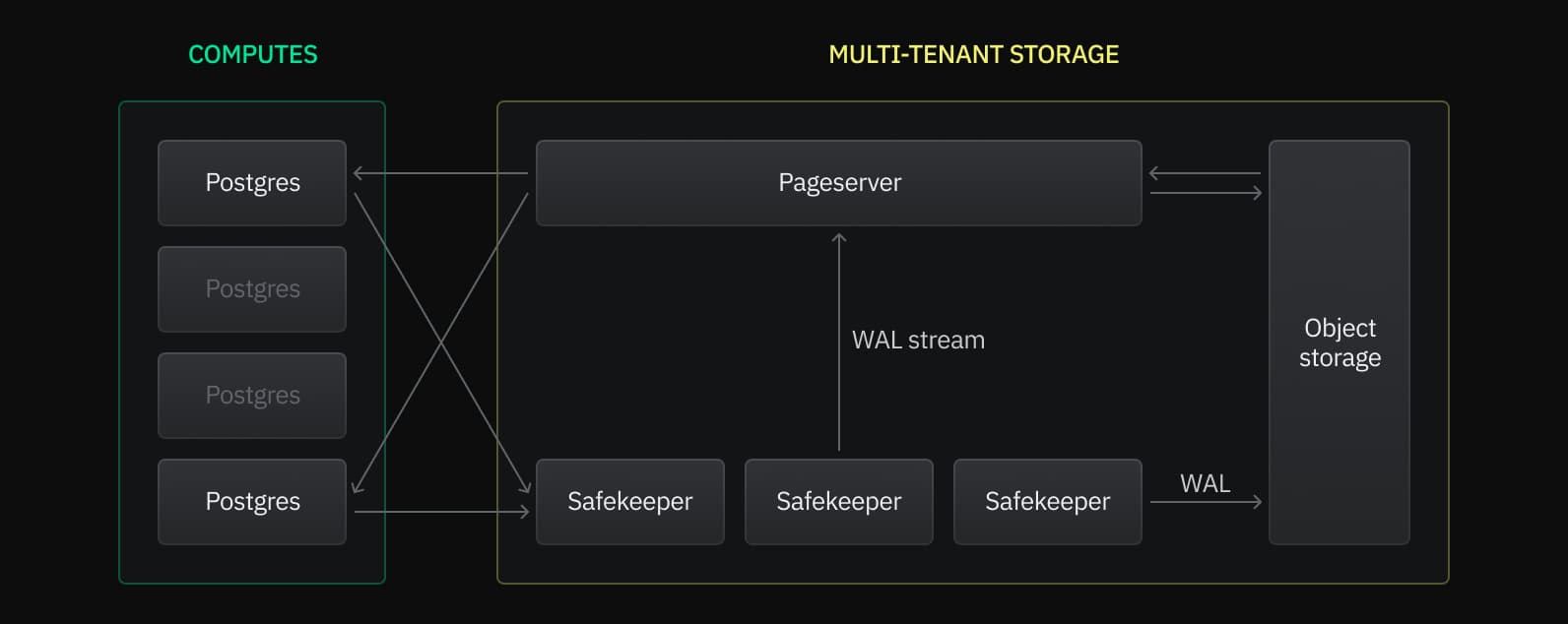
Based on this separation, we can break HA into two main parts:
-
Storage redundancy — Protecting both your long-term and active data
On the storage side, all data is backed by cloud object storage for long-term safety, while Pageserver and Safekeeper services are distributed across Availability Zones to provide redundancy for the cached data used by compute.
-
Compute resiliency — Keeping your application continuously connected
Our architecture scales to handle traffic spikes and automatically restarts your compute if Postgres crashes or your compute becomes unavailable.
Storage redundancy
By distributing storage components across multiple Availability Zones (AZs), Neon ensures both data durability and operational continuity.
General storage architecture
This diagram shows a simplified view of how failures of Safekeeper or Pageserver services are recovered across Availability Zones:
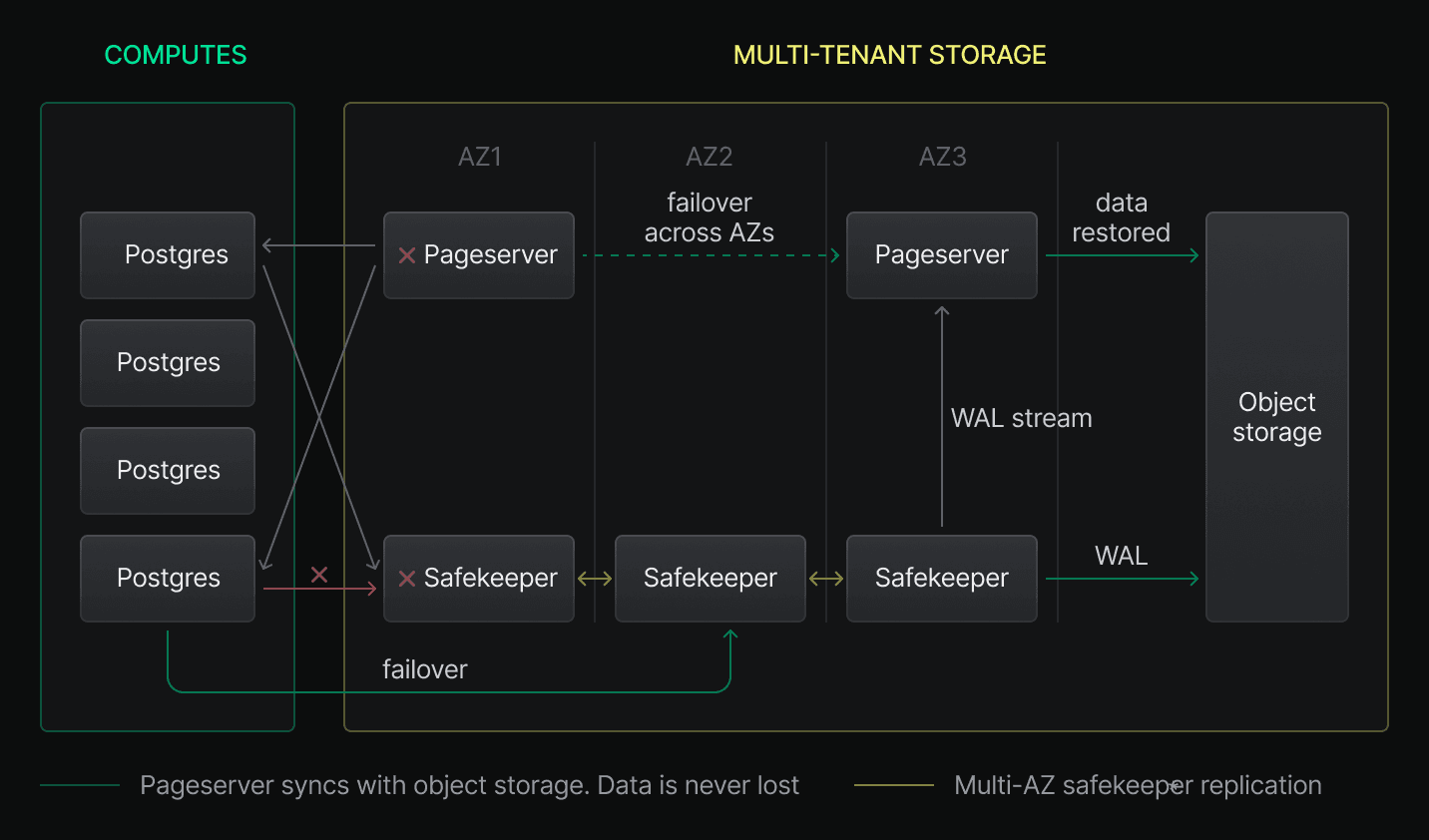
In this architecture:
-
Safekeepers replicate data across AZs
Safekeepers are distributed across multiple Availability Zones (AZs) to handle Write-Ahead Log (WAL) replication. WAL is replicated across these multi-AZ Safekeepers, ensuring your data is safe if any particular Safekeeper fails.
-
Pageservers
Pageservers act as a disk cache, ingesting and indexing data from the WAL stored by Safekeepers and serving that data to your compute. To ensure high availability, Neon employs secondary Pageservers that maintain up-to-date copies of project data.
In the event of a Pageserver failure, impacted projects are immediately reassigned to a secondary Pageserver, with minimal downtime. The system continuously monitors Pageserver health using a heartbeat mechanism to ensure timely detection and failover.
-
Object storage
The primary, long-term copy of your data resides in cloud object storage, with 99.999999999% durability, ensuring protection against permanent data loss in the event of Pageserver or Safekeeper failure.
Compute resiliency
While the compute layer doesn’t provide traditional high availability, it’s built for resiliency and quick recovery from failures. A Neon compute is stateless, meaning failures do not affect your data. In the most common compute failures, your connection remains stable. However, as with any stateless service, your application should be configured to reconnect automatically. Downtime usually lasts seconds, and your connection string stays the same.
Compute endpoints as metadata
Think of your compute endpoint as metadata — with your connection string being the core element. The endpoint isn't permanently tied to any specific resource but can be reassigned as needed. When you first connect to your database, Neon assigns a pre-created VM from a pool and attaches your compute endpoint to this VM.
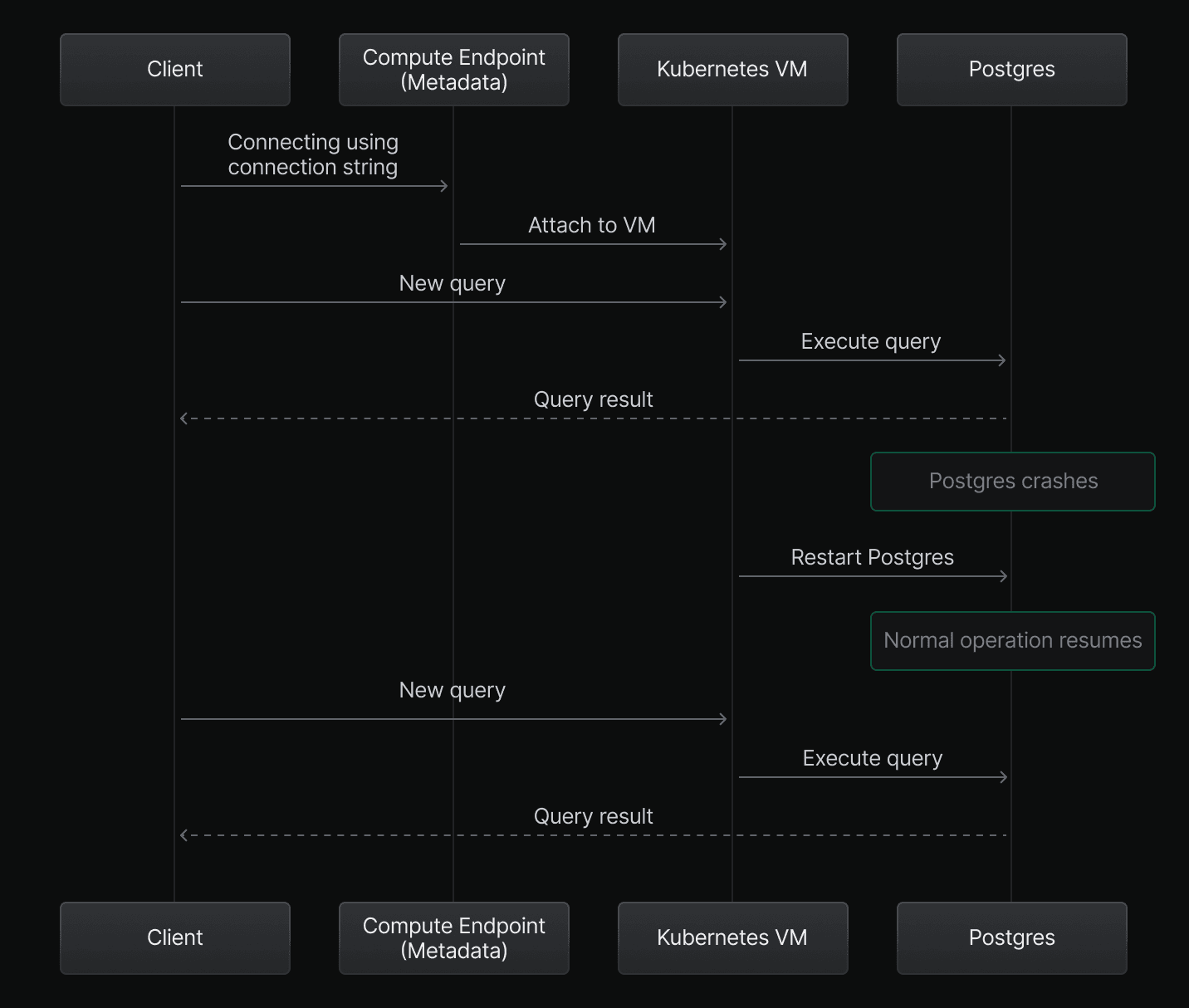
Postgres failure
Postgres runs inside the VM. If Postgres crashes, an internal Neon process detects the issue and automatically restarts Postgres. This recovery process typically completes within a few seconds.
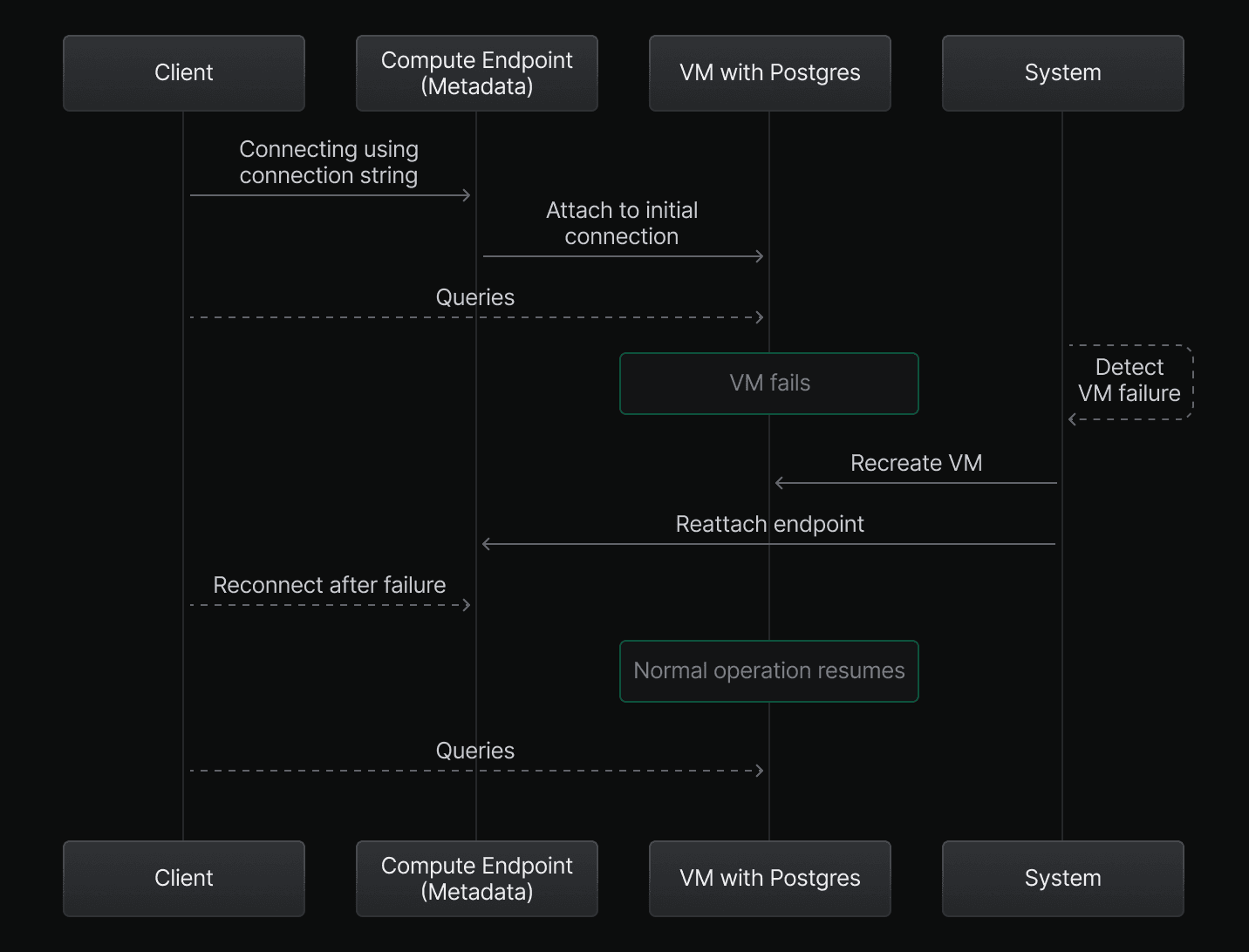
VM failure
In rarer cases, the VM itself may fail due to issues like a kernel panic or the host's termination. When this happens, Neon recreates the VM and reattaches your compute endpoint. This process may take a little longer than restarting Postgres, but it still typically resolves in seconds.
Impact on session data after a failure?
While your application should handle reconnections automatically, session-specific data like temporary tables, prepared statements, and the Local File Cache (LFC), which stores frequently accessed data, will not persist across a failover. As a result, queries may initially run more slowly until the Postgres memory buffers and cache are rebuilt.
For details on uptime and performance guarantees, refer to our available SLAs.
Limitations
No cross-region replication. Neon's HA architecture is designed to mitigate failures within a single region by replicating data across multiple AZs. However, we currently do not support real-time replication across different cloud regions. In the event of a region-wide outage, your data is not automatically replicated to another region, and availability depends on the cloud provider restoring service to the affected region.