Inngest
Quickly build AI RAG and Agentic workflows that scale with Inngest and Neon
Inngest is a popular framework for building AI RAG and Agentic workflows. Inngest provides automatic retries, caching along with concurrency and throttling management and AI requests offloading.
Inngest also integrates with Neon Postgres to trigger workflows based on database changes.
Build RAG with step.run()
Inngest provides a step.run() API that allows you to compose your workflows into cacheable, retryable, and concurrency-safe steps:
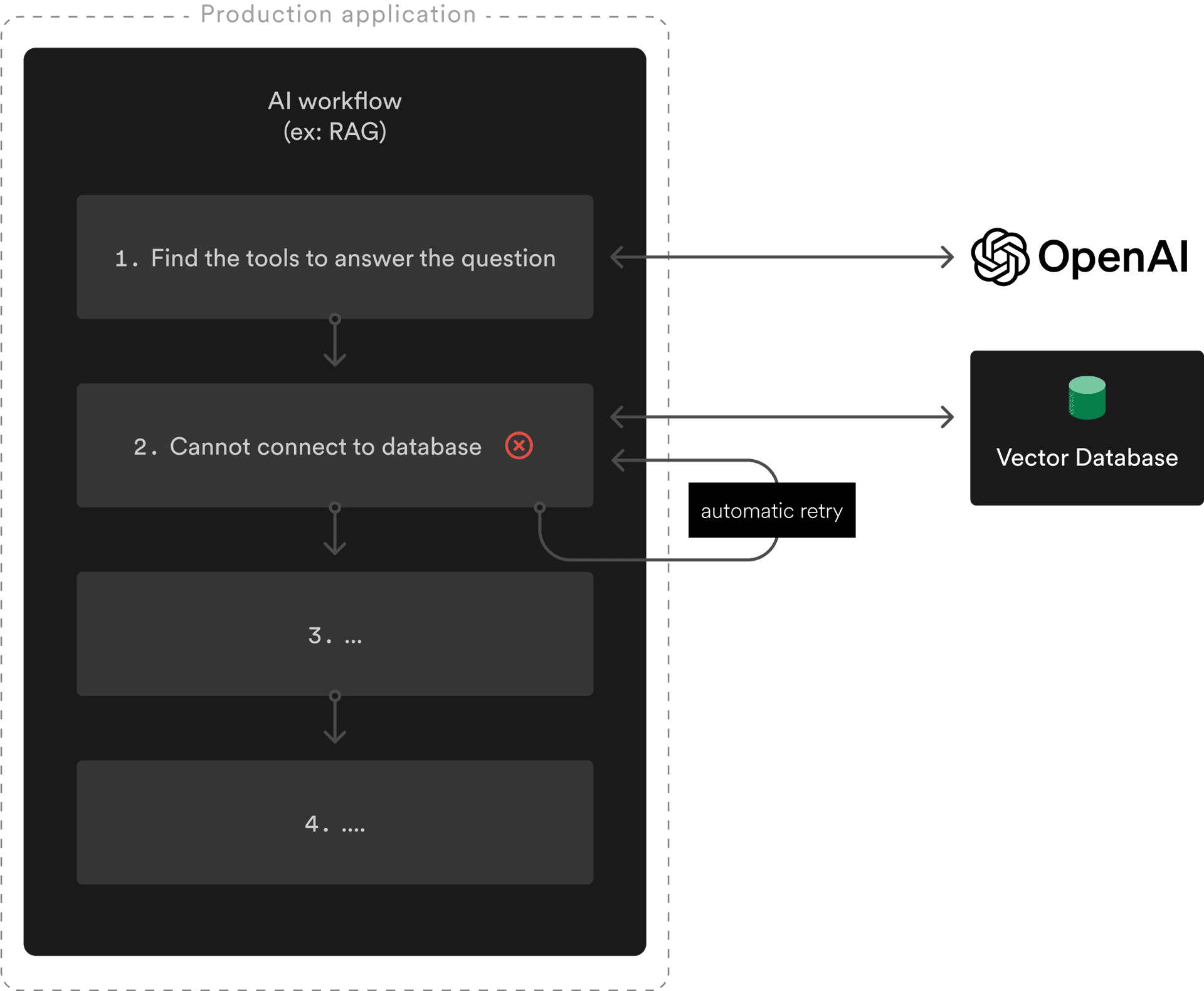
In the above workflow, a network issue prevented the AI workflow to connect to the vector store. Fortunately, Inngest retries the failed step and uses the cached results from the previous steps, avoiding an unnecessary additional OpenAI call.
This workflow translates to the following code:
import { inngest } from '@/inngest';
import { getToolsForMessage, vectorSearch } from '@/helpers';
export const ragWorkflow = client.createFunction(
{ id: 'rag-workflow', concurrency: 10 },
{ event: 'chat.message' },
async ({ event, step }) => {
const { message } = event.data;
const page = await step.run('tools.search', async () => {
// Calls OpenAI
return getToolsForMessage(message);
});
await step.run('vector-search', async () => {
// Search in Neon's vector store
return vectorSearch(page);
});
// step 3 and 4...
}
);Configuring concurrency or throttling to match your LLM provider's limits is achieved with a single line of code.
Learn more about using Inngest for RAG in the following article: Multi-Tenant RAG With One Neon Project Per User.
AI requests offloading: step.ai.infer()
Inngest also provides a step.ai.infer() API that offloads AI requests.
By using step.ai.infer() your AI workflows will pause while waiting for the slow LLM response, avoiding unnecessary compute use on Serverless environments:


The previous RAG workflow can be rewritten to use step.ai.infer() to offload the AI request to the LLM provider:
import { inngest } from '@/inngest';
import { getPromptForToolsSearch, vectorSearch } from '@/helpers';
export const ragWorkflow = client.createFunction(
{ id: 'rag-workflow', concurrency: 10 },
{ event: 'chat.message' },
async ({ event, step }) => {
const { message } = event.data;
const prompt = getPromptForToolsSearch(message);
await step.ai.infer('tools.search', {
model: openai({ model: 'gpt-4o' }),
body: {
messages: prompt,
},
});
// other steps...
}
);step.ai.infer(), combined with Neon's Scale-to-zero feature, allows you to build AI workflows that scale costs with its success!
Learn more about using step.ai.infer() in the following article: step.ai: Build Serverless AI Applications That Won't Break the Bank.
Trigger AI workflows based on database changes
Inngest also integrates with Neon Postgres to trigger AI workflows based on database changes:
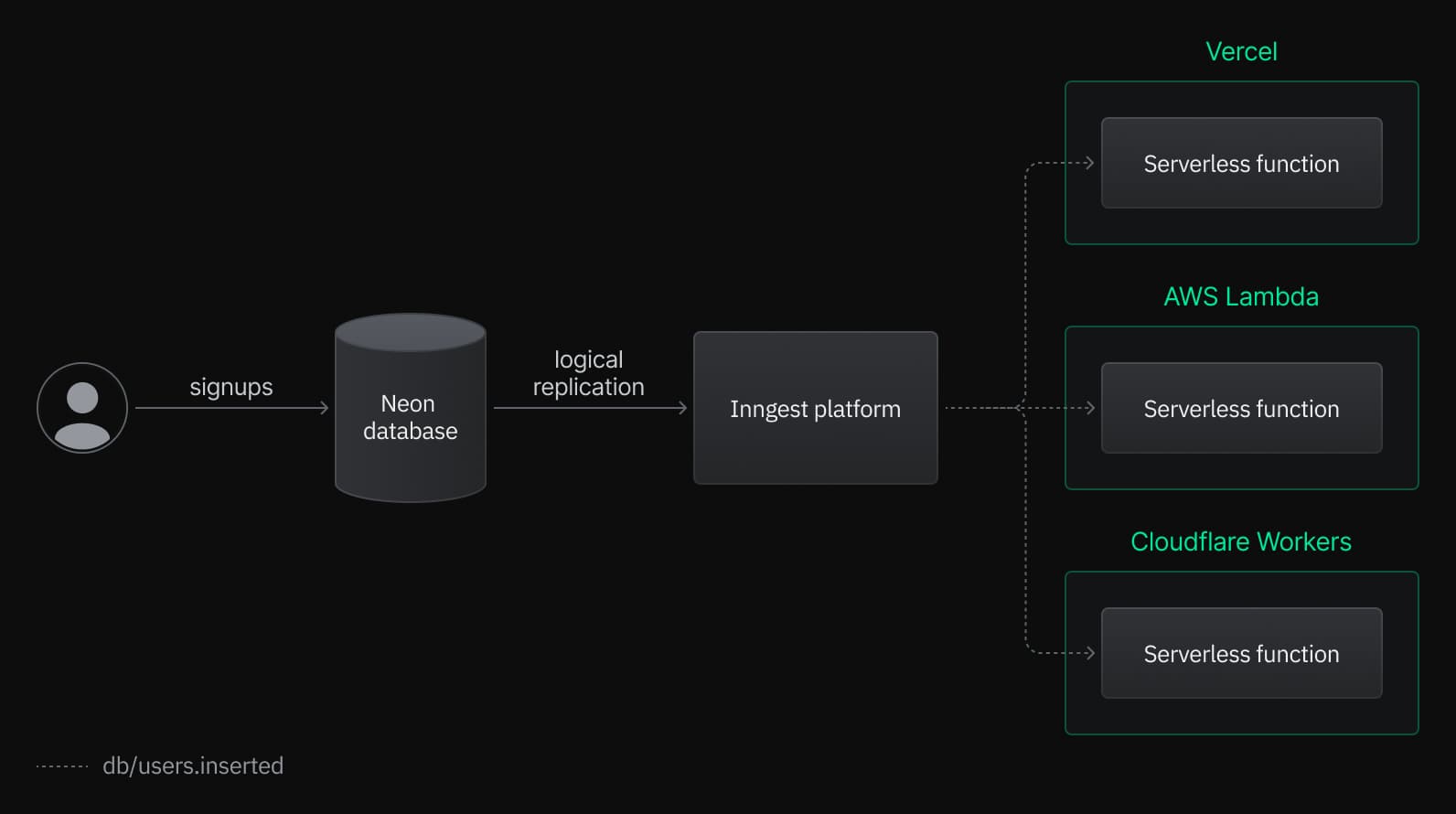
This integration allows you to trigger AI workflows based on database changes, such as generating embeddings as soon as a new row is inserted into a table (see example below).
Configure the Inngests Neon integration to trigger AI workflows from your Neon database changes by following this guide.
Starter apps
Hackable, fully-featured, pre-built starter apps to get you up and running with Inngest and Postgres.